片段管理
在该功能模块中,我们已完成以下几个核心功能:
- 数据库设计:为存储和管理片段数据提供结构化的支持。
- 用户登录:确保数据访问和操作的安全性。
- 知识库管理:支持知识库的创建、更新和删除。
- 文件拆分:将上传的文件拆分为多个片段,便于内容的精细化管理。
- 片段向量化:通过向量化技术,将片段内容转换为可计算的向量,便于相似度计算。
- 命中率测试:通过计算用户查询与片段的相似度来进行匹配测试。
- 文档管理:实现对不同文档内容的管理。
接下来,我们将实现 片段管理 功能,提供三个主要的 API 接口,使用户可以高效地访问和管理片段的内容数据。
功能概述
片段管理 功能包括以下主要操作:
- 获取片段列表:根据数据集 ID 和文档 ID 分页获取片段列表。
- 添加问题到片段:为指定的片段添加问题。
- 获取片段的问题列表:获取指定片段下的所有问题。
接口定义
以下是片段管理的三个主要接口定义:
1. 获取片段列表
接口 URL: http://localhost:3000/api/dataset/{datasetId}/document/{documentId}/paragraph/{pageNo}/{pageSize}
请求方法: GET
- 路径参数:
datasetId(Long):数据集的唯一标识符。documentId(Long):文档的唯一标识符。pageNo(Integer):当前页码。pageSize(Integer):每页显示的记录数。
示例请求
GET http://localhost:3000/api/dataset/443309276048408576/document/443662133182980096/paragraph/1/20
响应
{
"message": null,
"data": {
"size": 20,
"total": 6,
"current": 1,
"records": [
{
"update_time": 1730853305661,
"is_active": true,
"create_time": 1730853305661,
"id": "443662143056371712",
"title": "",
"document_id": "443662133182980096",
"content": "...."
}
]
},
"code": 200
}
响应字段说明
message: 错误或提示信息,成功时为null。data: 数据对象,包含分页信息和片段记录。size: 每页的记录数。total: 总记录数。current: 当前页码。records: 包含片段信息的列表,每条记录包含以下字段:update_time: 片段最后一次更新的时间戳。is_active: 片段的状态,true表示启用,false表示禁用。create_time: 片段的创建时间戳。id: 片段的唯一标识符。title: 片段的标题(如果有)。document_id: 所属文档的标识符。content: 片段的具体内容。
code: 响应状态码,200表示成功。
2. 添加问题到片段
接口 URL: http://localhost:3000/api/dataset/{datasetId}/document/{documentId}/paragraph/{paragraphId}/problem
请求方法: POST
路径参数:
datasetId(Long):数据集的唯一标识符。documentId(Long):文档的唯一标识符。paragraphId(Long):片段的唯一标识符。
请求体:
{
"content": "Exam Schedule"
}
示例请求
POST http://localhost:3000/api/dataset/443309276048408576/document/443662133182980096/paragraph/443662151243653120/problem
Content-Type: application/json
{
"content": "Exam Schedule"
}
响应
{
"message": null,
"data": {
"id": "444734959665311744",
"content": "Exam Schedule",
"dataset_id": "443309276048408576"
},
"code": 200
}
响应字段说明
message: 错误或提示信息,成功时为null。data: 新添加的问题对象,包含以下字段:id: 问题的唯一标识符。content: 问题的内容。dataset_id: 所属数据集的标识符。
code: 响应状态码,200表示成功。
3. 获取片段的问题列表
接口 URL: http://localhost:3000/api/dataset/{datasetId}/document/{documentId}/paragraph/{paragraphId}/problem
请求方法: GET
- 路径参数:
datasetId(Long):数据集的唯一标识符。documentId(Long):文档的唯一标识符。paragraphId(Long):片段的唯一标识符。
示例请求
GET http://localhost:3000/api/dataset/443309276048408576/document/443662133182980096/paragraph/443662151243653120/problem
响应
{
"message": null,
"data": [
{
"id": "444734959665311744",
"content": "office hour",
"dataset_id": "443309276048408576"
},
{
"id": "444831888056446976",
"content": "class time",
"dataset_id": "443309276048408576"
}
],
"code": 200
}
响应字段说明
message: 错误或提示信息,成功时为null。data: 问题列表数组,每个问题包含以下字段:id: 问题的唯一标识符。content: 问题的内容。dataset_id: 所属数据集的标识符。
code: 响应状态码,200表示成功。
代码实现
以下是 片段管理 功能的核心代码实现,包括 API 控制器和服务层。
1. API 控制器
文件:ApiDatasetController.java
import com.litongjava.annotation.Get;
import com.litongjava.annotation.Post;
import com.litongjava.annotation.RequestPath;
import com.litongjava.jfinal.aop.Aop;
import com.litongjava.maxkb.service.MaxKbParagraphServcie;
import com.litongjava.model.result.ResultVo;
import com.litongjava.tio.boot.http.HttpRequest;
import com.litongjava.tio.boot.http.TioRequestContext;
import com.litongjava.tio.utils.json.JsonUtils;
@RequestPath("/api/dataset")
public class ApiDatasetController {
/**
* 获取指定文档下的片段列表(分页)
*
* @param datasetId 数据集 ID
* @param documentId 文档 ID
* @param pageNo 当前页码
* @param pageSize 每页片段数量
* @return ResultVo 包含分页片段列表
*/
@Get("/{datasetId}/document/{documentId}/paragraph/{pageNo}/{pageSize}")
public ResultVo listParagraph(Long datasetId, Long documentId, Integer pageNo, Integer pageSize) {
Long userId = TioRequestContext.getUserIdLong();
return Aop.get(MaxKbParagraphServcie.class).page(userId, datasetId, documentId, pageNo, pageSize);
}
/**
* 获取指定片段下的问题列表
*
* @param datasetId 数据集 ID
* @param documentId 文档 ID
* @param paragraphId 片段 ID
* @return ResultVo 包含问题列表
*/
@Get("/{datasetId}/document/{documentId}/paragraph/{paragraphId}/problem")
public ResultVo listProblem(Long datasetId, Long documentId, Long paragraphId) {
Long userId = TioRequestContext.getUserIdLong();
return Aop.get(MaxKbParagraphServcie.class).listProblemByParagraphId(datasetId, documentId, paragraphId);
}
/**
* 添加问题到指定片段
*
* @param datasetId 数据集 ID
* @param documentId 文档 ID
* @param paragraphId 片段 ID
* @param request HTTP 请求对象,包含请求体
* @return ResultVo 添加结果
*/
@Post("/{datasetId}/document/{documentId}/paragraph/{paragraphId}/problem")
public ResultVo addProblem(Long datasetId, Long documentId, Long paragraphId, HttpRequest request) {
String bodyString = request.getBodyString();
String content = JsonUtils.parseToMap(bodyString, String.class, String.class).get("content");
return Aop.get(MaxKbParagraphServcie.class).addProblemById(datasetId, documentId, paragraphId, content);
}
}
代码说明
- 注解
@RequestPath("/api/dataset"):定义控制器的基础路径为/api/dataset。 - 方法
listParagraph:- 注解
@Get("/{datasetId}/document/{documentId}/paragraph/{pageNo}/{pageSize}"):定义 GET 请求路径。 - 参数:
datasetId:数据集 ID。documentId:文档 ID。pageNo:当前页码。pageSize:每页片段数量。
- 功能:获取指定文档下的分页片段列表。
- 注解
- 方法
listProblem:- 注解
@Get("/{datasetId}/document/{documentId}/paragraph/{paragraphId}/problem"):定义 GET 请求路径。 - 参数:
datasetId:数据集 ID。documentId:文档 ID。paragraphId:片段 ID。
- 功能:获取指定片段下的所有问题列表。
- 注解
- 方法
addProblem:- 注解
@Post("/{datasetId}/document/{documentId}/paragraph/{paragraphId}/problem"):定义 POST 请求路径。 - 参数:
datasetId:数据集 ID。documentId:文档 ID。paragraphId:片段 ID。request:包含请求体的 HTTP 请求对象。
- 功能:为指定的片段添加一个新问题。
- 注解
- 依赖注入:通过
Aop.get(MaxKbParagraphServcie.class)获取MaxKbParagraphServcie服务实例。
2. 服务层
文件:MaxKbParagraphServcie.java
package com.litongjava.maxkb.service;
import java.util.ArrayList;
import java.util.List;
import com.jfinal.kit.Kv;
import com.litongjava.db.TableInput;
import com.litongjava.db.TableResult;
import com.litongjava.db.activerecord.Db;
import com.litongjava.db.activerecord.Row;
import com.litongjava.kit.RecordUtils;
import com.litongjava.maxkb.constant.TableNames;
import com.litongjava.maxkb.model.ResultPage;
import com.litongjava.model.page.Page;
import com.litongjava.model.result.ResultVo;
import com.litongjava.table.services.ApiTable;
import com.litongjava.tio.utils.snowflake.SnowflakeIdUtils;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class MaxKbParagraphServcie {
/**
* 分页获取片段列表
*
* @param userId 用户 ID
* @param datasetId 数据集 ID
* @param documentId 文档 ID
* @param pageNo 当前页码
* @param pageSize 每页片段数量
* @return ResultVo 包含分页片段列表
*/
public ResultVo page(Long userId, Long datasetId, Long documentId, Integer pageNo, Integer pageSize) {
log.info("datasetId:{}, documentId:{}", datasetId, documentId);
TableInput tableInput = new TableInput();
tableInput.setColumns("id, title, content, is_active, document_id, create_time, update_time");
tableInput.set("dataset_id", datasetId)
.set("document_id", documentId)
.setPageNo(pageNo)
.setPageSize(pageSize);
TableResult<Page<Row>> tableResult = ApiTable.page(TableNames.max_kb_paragraph, tableInput);
Page<Row> page = tableResult.getData();
int totalRow = page.getTotalRow();
List<Row> records = page.getList();
List<Kv> kvs = RecordUtils.recordsToKv(records, false);
ResultPage<Kv> resultPage = new ResultPage<>(pageNo, pageSize, totalRow, kvs);
return ResultVo.ok(resultPage);
}
/**
* 获取指定片段下的问题列表
*
* @param datasetId 数据集 ID
* @param documentId 文档 ID
* @param paragraphId 片段 ID
* @return ResultVo 包含问题列表
*/
public ResultVo listProblemByParagraphId(Long datasetId, Long documentId, Long paragraphId) {
String sql = "SELECT p.id, p.content, p.dataset_id " +
"FROM max_kb_problem p " +
"JOIN max_kb_problem_paragraph_mapping mapping ON mapping.problem_id = p.id " +
"WHERE mapping.paragraph_id = ?";
List<Row> records = Db.find(sql, paragraphId);
List<Kv> kvs = RecordUtils.recordsToKv(records, false);
return ResultVo.ok(kvs);
}
/**
* 批量添加问题到指定片段
*
* @param datasetId 数据集 ID
* @param documentId 文档 ID
* @param paragraphId 片段 ID
* @param problems 问题内容列表
* @return ResultVo 添加结果
*/
public ResultVo addProblemsById(Long datasetId, Long documentId, Long paragraphId, List<String> problems) {
List<Row> problemRecords = new ArrayList<>();
List<Row> mappings = new ArrayList<>();
for (String str : problems) {
long problemId = SnowflakeIdUtils.id();
problemRecords.add(Row.by("id", problemId)
.set("dataset_id", datasetId)
.set("hit_num", 0)
.set("content", str));
long mappingId = SnowflakeIdUtils.id();
mappings.add(Row.by("id", mappingId)
.set("dataset_id", datasetId)
.set("document_id", documentId)
.set("paragraph_id", paragraphId)
.set("problem_id", problemId));
}
Db.tx(() -> {
Db.batchSave(TableNames.max_kb_problem, problemRecords, 2000);
Db.batchSave(TableNames.max_kb_problem_paragraph_mapping, mappings, 2000);
return true;
});
return ResultVo.ok("问题添加成功");
}
/**
* 添加单个问题到指定片段
*
* @param datasetId 数据集 ID
* @param documentId 文档 ID
* @param paragraphId 片段 ID
* @param content 问题内容
* @return ResultVo 添加结果
*/
public ResultVo addProblemById(Long datasetId, Long documentId, Long paragraphId, String content) {
long problemId = SnowflakeIdUtils.id();
Row problem = Row.by("id", problemId)
.set("dataset_id", datasetId)
.set("hit_num", 0)
.set("content", content);
long mappingId = SnowflakeIdUtils.id();
Row mapping = Row.by("id", mappingId)
.set("dataset_id", datasetId)
.set("document_id", documentId)
.set("paragraph_id", paragraphId)
.set("problem_id", problemId);
Db.tx(() -> {
Db.save(TableNames.max_kb_problem, problem);
Db.save(TableNames.max_kb_problem_paragraph_mapping, mapping);
return true;
});
return ResultVo.ok("问题添加成功");
}
}
代码说明
- 方法
page:- 参数:
userId:当前用户的 ID,用于权限控制。datasetId:数据集 ID,用于过滤片段。documentId:文档 ID,用于过滤片段。pageNo:当前页码。pageSize:每页片段数量。
- 功能:
- 创建
TableInput对象,设置查询列、数据集 ID、文档 ID、页码和页大小。 - 调用
ApiTable.page方法执行分页查询,获取TableResult。 - 从
TableResult中提取Page<Row>对象,获取总行数和记录列表。 - 将记录列表转换为键值对列表 (
List<Kv>)。 - 构建
ResultPage<Kv>对象,包含分页信息和片段列表。 - 返回成功的
ResultVo对象,包含ResultPage数据。
- 创建
- 参数:
- 方法
listProblemByParagraphId:- 参数:
datasetId:数据集 ID。documentId:文档 ID。paragraphId:片段 ID。
- 功能:
- 定义 SQL 查询,联接问题表和问题-片段映射表,筛选指定片段的所有问题。
- 执行查询,获取问题记录列表。
- 将记录列表转换为键值对列表 (
List<Kv>)。 - 返回成功的
ResultVo对象,包含问题列表数据。
- 参数:
- 方法
addProblemsById:- 参数:
datasetId:数据集 ID。documentId:文档 ID。paragraphId:片段 ID。problems:问题内容列表。
- 功能:
- 遍历问题内容列表,为每个问题生成唯一 ID,并创建问题记录和映射记录。
- 执行数据库事务,批量保存问题记录和映射记录。
- 返回成功的
ResultVo对象,包含添加结果信息。
- 参数:
- 方法
addProblemById:- 参数:
datasetId:数据集 ID。documentId:文档 ID。paragraphId:片段 ID。content:问题内容。
- 功能:
- 生成唯一的
problemId和mappingId。 - 创建问题记录和映射记录。
- 执行数据库事务,保存问题记录和映射记录。
- 返回成功的
ResultVo对象,包含添加结果信息。
- 生成唯一的
- 参数:
- 依赖组件:
ApiTable:用于执行数据库表的分页查询和单条记录查询。RecordUtils:用于将数据库记录转换为键值对格式。ResultVo和ResultPage:用于标准化 API 响应结构。SnowflakeIdUtils:用于生成唯一的 ID。Db:用于数据库操作,支持事务管理。
权限控制
在上述实现中,我们假设 userId 为 1 的用户为管理员,具有管理所有数据集和片段的权限。非管理员用户只能管理和访问自己创建的数据集和片段。这种权限控制确保了数据的安全性和隐私性。
异常处理
当前实现未详细展示异常处理逻辑。建议在实际开发中加入以下内容:
- 参数校验:确保请求参数的有效性,如
datasetId、documentId和paragraphId的存在性、pageNo和pageSize的合理性。 - 权限验证:在服务层进一步验证用户是否有权访问指定的数据集、文档和片段。
- 错误响应:在发生异常时,返回适当的错误消息和状态码,如
400 Bad Request、401 Unauthorized、404 Not Found等。
测试
为了确保片段管理功能的正确性和稳定性,建议编写以下测试用例:
- 获取片段列表:
- 查询存在的数据集和文档,验证返回的片段列表是否正确。
- 查询不存在的数据集或文档,验证返回的错误信息。
- 测试不同的
pageNo和pageSize参数,确保分页逻辑正确。
- 添加问题到片段:
- 向存在的片段添加问题,验证问题是否成功添加。
- 向不存在的片段添加问题,验证返回的错误信息。
- 添加空内容的问题,验证系统的处理方式。
- 获取片段的问题列表:
- 查询存在的片段,验证返回的问题列表是否正确。
- 查询不存在的片段,验证返回的错误信息。
- 验证权限控制,确保用户无法访问未授权的片段的问题。
显示效果
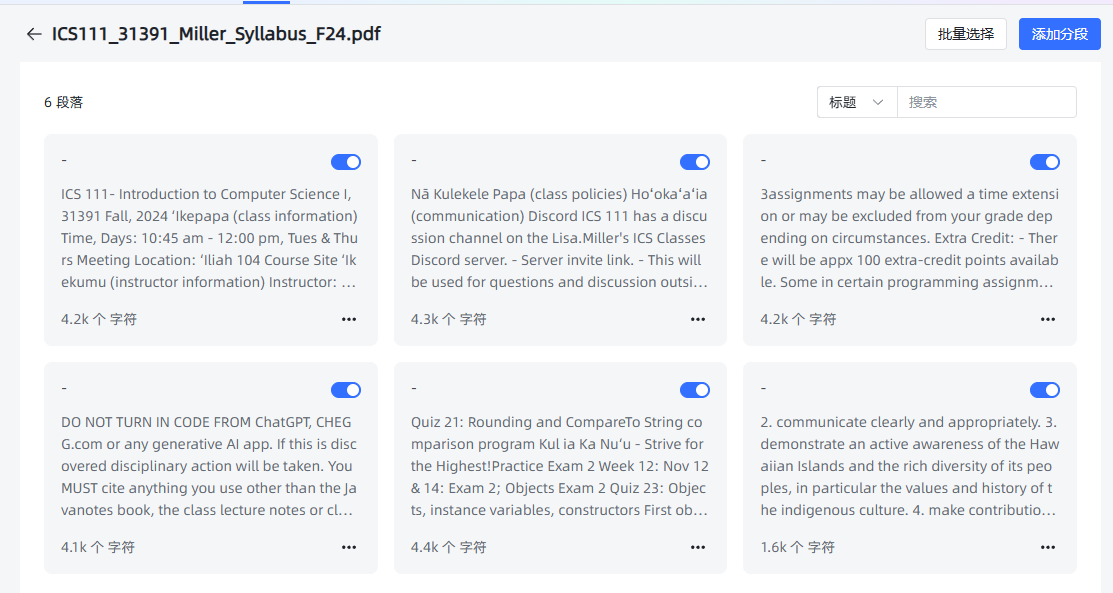
总结
通过上述接口和代码实现,我们成功地为系统添加了片段管理功能。该功能允许用户根据数据集和文档管理和检索片段,支持分页查询、问题的添加与查看。未来,可以进一步扩展此功能,如添加片段编辑、删除、批量操作等,以满足更全面的片段管理需求。